【offer 收割计划】你知道为什么 reducer 最好是一个纯函数吗?

📢 大家好,我是小丞同学,一名大二的前端爱好者
📢 这篇文章将来讲讲最近无意中看到的几道面试题,也希望来看看大家的理解~
📢 非常感谢你的阅读,不对的地方欢迎指正 🙏
📢 愿你忠于自己,热爱生活
前言
最近看了看了下一些博主的面试文,自己也跟着思考了一下一些题目,发现有很多简单而又重要的知识点有点拿捏不住,因此决定写一个专栏,来记录这些题目,并写上自己的理解,更重要的是,希望有读者能够分享自己的理解,或者在哪些题目遇到了问题,这样我们可以一起关注一下这些题目,大家共同进步!因此希望在读这篇文章的你,可以自己先思考一下,再看看我的理解,这样也能起到对我的文章正确性的检验。
- 如果文章内容有什么错误的地方,也请大家务必指出!
- 如果期待本专栏的新文章,也可以评论留言噢!
- 如果你是同龄人,或者有什么需求,可以添加我的 vx 和我一起探讨!
💡 知识点抢先看
for...in和for ... of的区别splice和slice的区别includes和indexOf的差异- 伪类的作用
ajax状态码redux中的reducer为什么最好是一个纯函数?
一、你能说说 for ... in 和 for ... of 的区别吗?
简单来说 for...in 和 for ... of 都是用来遍历的,但是for ... in 遍历的是数组的索引 index,而 for ... of 遍历的是数组的元素值 value
先说说 for ...of
✅ 它只能遍历部署了 iterator 接口的数据结构,对象如果不实现 iterator 接口,也是无法使用 for ... of 遍历的
✅ for ... of 不只是可以遍历元素的 value 值,你也可以通过下面这种方式来遍历出对象的 key, value 值,但是这样会相对的麻烦一些,因此不推荐 for ... of 来遍历对象

✅ for...of 更适合遍历数组,并且它只是遍历数组内的元素,不会遍历原型属性以及自身的属性

再来看看 for ... in
for ... in 更适合遍历对象,在用来遍历数组的时候,由于 for ... in 的特性会造成一些问题
✅ for ... in 会遍历出数组的原型对象,以及数组自身的属性,因此下面的 index 中会打印出 a
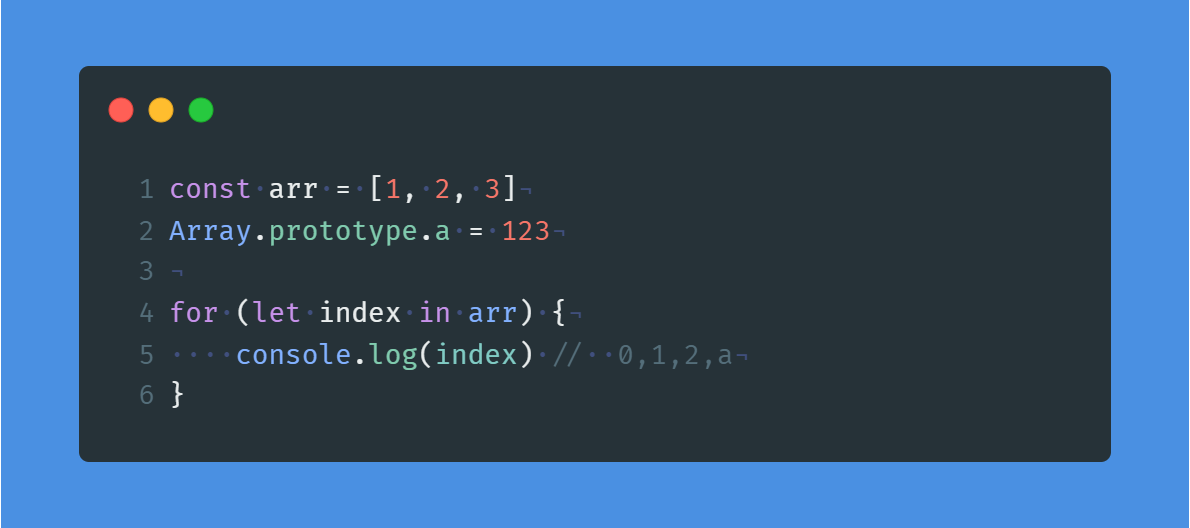
✅ 同时值得注意的是,for ... in 遍历出来的 index 并不是一个 number 类型,而是一个 string 类型,因此在使用 index 来进行计算的时候需要注意

👉 总结以上,for ... in 和 for ... of 的区别有以下几点
for ... in循环出的是index,for ... of循环出的是valuefor ... of不能循环普通对象,需要实现iterator接口for ... of不会遍历原型以及自身的属性,而for ... in会for ... of是ES6的新语法
二、来说说数组里的 slice 和 splice 方法
slice 方法主要是用来截取数组以及字符串,它接收两个参数,一个是截取的起始位置,一个是截取的结束位置,同时它会返回截取元素组成的新数组,并且不会改变原数组
可以看到从索引为 1 的地方截取到索引为 3 的地方结束,返回的是一个被截取的数组,同时原数组没有被改变

splice 方法主要用来删除数组,并且可以添加数组元素,它接收的第一个参数是起始的索引,第二个参数是删除的个数,后面的参数都是需要添加的元素
第二个参数以后的参数是需要增加的元素,在起始位置插入,可以理解为,删除了一些元素,然后在这里补上一些新的元素,splice 会改变原数组

可以看到从索引为 1 的地方开始(包括 1),开始删除 2 个元素,也就是 b,c ,随后在这里补上了 2 个元素,同时也可以看出原数组 arr 被改变了
👉 总结以上:
- 两者并没有什么直接的关联,
splice用来增删数组,slice用来截取数组或字符串 splice会改变原数组,slice不会改变原数组
三、为什么有了 indexOf 方法,在 ES7 中还要新增 includes 方法呢?
在之前的 indexOf 方法中存在着一些问题,主要是在于 NaN 的判断上,indexOf 没有办法去判断数组中是否存在 NaN 值,当我们需要判断数组中是否存在 NaN 值的时候,我们需要采用 includes 来判断
采用 indexOf 就会出现下面这样的差异
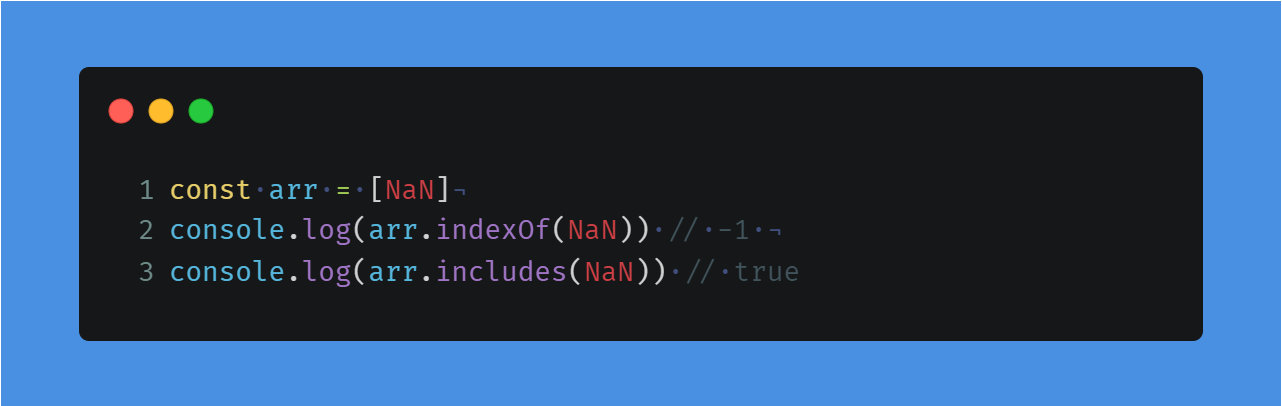
同时当数组有空值的时候, includes 会认为空值为 undefined ,而 indexOf 不会,再来看段代码

因此,includes 的出现就是为了解决 indexOf 遗留的一些问题
👉 总结以上:
includes能够判断数组中有无NaN值includes会把空值默认成undefined- 如果想要判断数组中是否存在某个值,可以采用
includes,查找数组中某个值的位置可以采用indexOf
四、伪元素有哪些作用呢?
在谈作用之前,先来区分一下伪元素和伪类
伪类:从字面上来看,可以理解为一个 CSS 类,它就是用来选择处于特定状态的元素的选择器,比如处于 hover 状态的元素,某个 class 的第几个元素,它和普通的类不一样。此外伪类一般是单冒号,例如 :hover
伪元素:从字面上看,它是一个假的元素,我也是这么理解的,它类似添加一个新的 DOM 节点到 DOM 树上,而不是改变元素的状态。但是这里值得注意的是,这里不是真的添加一个节点,实际上这个元素被创建在文档之外。
为了从写法上区分伪类和位元素,一般伪元素采用双冒号,例如 ::after ,但是对于伪元素来说,单冒号,双冒号都可以,建议规范
回归正题
伪元素的作用
- 伪元素能够减少页面中的
DOM节点,伪元素不属于 HTML 页面,能够减小JS查找DOM的负担,因此可以说,使用伪元素能够优化性能 - 伪元素能够用来清除浮动,经典三件套
content,displayclear - 加快浏览器加载 HTML 文件
五、500 HTTP 状态码是什么异常?
500 是服务器内部错误
常见的HTTP 状态码
HTTP 状态码 | means |
|---|---|
| 200 | 服务器成功返回网页 |
| 301 | 对象永久移动 |
| 302 | 对象临时移动 |
| 304 | 请求的网页未修改 |
| 401 | 未授权,请求要求身份验证 |
| 404 | 请求的网页不存在 |
| 500 | 服务器内部错误 |
| 503 | 服务不可用 |
六、redux 中的 reducer 要求是一个纯函数呢?
首先如果 redux 中的 reducer 如果不是一个 纯函数的话会造成什么后果呢?
如果我们在 reducer 中,在原来 state 的基础上进行操作的话,并不会让 React 组件重新渲染,并不会有任何改变,这是由于 Redux 的底层实现决定的
在这里我们看看 redux 的源码,来看看它到底是什么原因造成的,Redux 接收一个 state 对象,然后通过 for 循环,将 state 的每一部分传递给对于的 reducer ,如果发生任何改变, reducer 将返回一个新的对象,也就是这里的 hasChanged 判断,我们可以发现,它只是通过了 !== 来进行判断前后的 state 是否相等,这是一种浅比较的方法,我的理解就是地址有没有变化
因此如果我们传入的 state 是在旧的基础上更改的,那么它的地址是不会发生变化的,因此是不会通过这层浅比较的,因此 hasChanged 返回 false ,state 没有被更新
那为什么 redux 要这样设计呢?
如果这里改成深比较不就没有这种问题了吗?
原因是,如果这里采用了深比较的方式,当比较的次数很多时,性能消耗特别大,因此 redux 对 reducer 做了一个规定,无论发生什么变化时,都需要返回一个新的对象;没有变化时,返回旧的对象。这样就能继续沿用浅比较的方式,很好的减少了性能的损耗
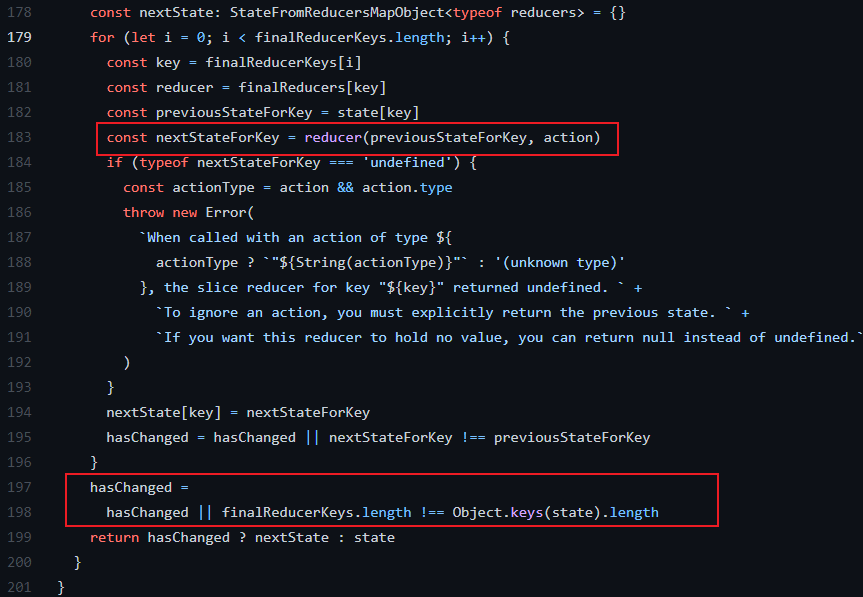
同时在 redux 的英文官网中给 reducers 定制了一套规则:对应地址
We said earlier that reducers must always follow some special rules:
- They should only calculate the new state value based on the
stateandactionarguments- They are not allowed to modify the existing
state. Instead, they must make immutable updates, by copying the existingstateand making changes to the copied values.- They must not do any asynchronous logic or other "side effects"
蹩脚翻译
我们之前说过,reducer 必须始终遵循一些特殊规则
- 它们应该只根据
state和action参数计算新的状态值- 它们不允许修改当前的
state。相反,它们必须通过复制现在的state,并对复制的值进行更改来进行state更新- 它们不能做任何异步逻辑以及其他”副作用“
遵循这些规则的函数也被称为**“纯”函数**,因此 reducer 需要一个纯函数由此而来
👉 总结以下
redux底层采用了浅比较的方式来判断state改变,来优化性能- 采用纯函数,保证新旧
state不是同一个对象引用 - 为了保证返回新的
state是确定的,不会因为副作用返回不确定的state
📖 总结
通过这几道面试题,我们复习了 JavaScript 中的循环语句,也区分了 splice 和 slice 而又深入理解 redux 中 reducer 的工作原理,这对我自己来说提升还是很大的,不知道看到这里的你有没有什么收获呢?可能文中有理解不到位的地方,欢迎在评论区指出,我们一起进步,共同成长!
最后,我是小丞同学,欢迎大家关注本专栏,持续关注最新文章~祝愿大家拿到心仪的 offer
最后,可能在很多地方讲诉的不够清晰,请见谅
💌 如果文章有什么错误的地方,或者有什么疑问,欢迎留言,也欢迎私信交流