📢 大家好,我是小丞同学,一名
准大二的前端爱好者📢 这篇文章将带你了解 V8 是如何执行 JS 代码的
📢
愿你忠于自己,热爱生活
引言

源代码首先通过解析器解析成 AST ,然后 AST 再通过解释器解释成最终的字节码
下面我们来聊聊解析器解析成 AST 的这个过程
首先我们先了解一下什么是 AST
🍉 1. 生成 AST
AST 中文名叫抽象语法树,它是源代码语法结构的一种抽象表示
它以树状的形式表现编程语言的语法结构,书上的每个节点都表示源代码中的一种结构
下面我们来一个例子看看 AST 是如何产生的
let name = "ljc";我们定义了一个 name 变量
解析器第一步要做的就是把这个语句拆分成最小的不可拆分的单元

生成 token 流,即语法单元成的数组
[
{
"type": "Keyword",
"value": "let"
},
{
"type": "Identifier",
"value": "name"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "String",
"value": "ljc"
},
{
"type": "Punctuator",
"value": ";"
}
]第二步就是语法分析
将上一步的 token 数据,转为 AST,得到一个树状结构
因此 AST 也被称为抽象语法树
在生成 AST 的同时,V8 还会生成相关的作用域,作用域中存放相关变量
🍏 2. 生成字节码
在有了 AST 和作用域之后,就可以生成字节码了,字节码是介于 AST 和机器码之间的一种代码,可以不需要将其转换成机器码后再执行,字节码可以理解为是机器码的一种抽象。Ignition 解释器除了可以快速生成没有优化的字节码外,还可以执行部分字节码。
那为什么需要生成字节码呢?直接转换为机器代码不是更好吗?
- 直接转换会带来内存占用过大的问题,因为如果抽象语法树全部生成机器代码,而机器代码相比于字节码,占用的内存要多的多
这是网上的一张对比图

- 某些 JavaScript 使用场景使用解释器更为合适,解析成字节码,有些没有必要的代码就可以不生产机器代码,这样可以尽可能的减少占用内存过大的问题
🍒 3. 执行代码及优化
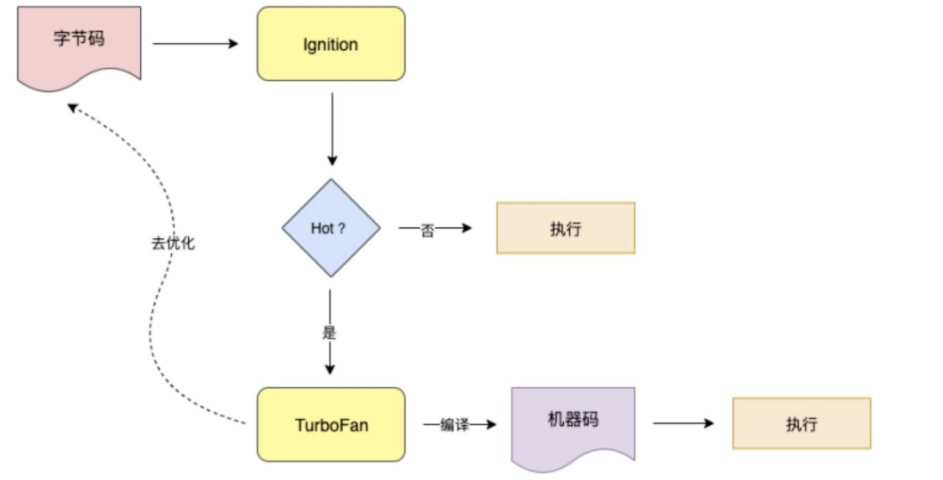
在上一步生成的字节码,直接被解释器执行,在代码不断地运行过程中,解释器会收到很多可以用来优化代码的信息,比如变量的类型,哪些函数执行的频率较高,这些信息会被发生个编译器 TruboFan ,它会根据这些信息和字节码来编译出经过优化的机器代码。
运行时几个优化策略
- 函数只声明未被调用,不会被解析生成 AST
- 函数只被调用一次,字节码会直接被解释执行
- 函数被调用多次,可能会被标记为热点函数,可能会被编译成机器代码
关于热点函数
编译器 TurboFan 会将这些热点代码编译成更高效的机器代码储存起来,等到下次再执行时,会用现在的机器代码替换原来的字节码进行执行,这样就会大大的提示代码的执行效率。同时当 TurboFan 判断一段代码不再为热点代码的时候,会执行去优化的过程,把优化的机器码丢掉,然后执行过程回到解释器。
有时候解释器收集到的一些信息会是错误的,这就会导致 TurboFan 生成机器代码后,会被逆向还原成字节码
例如:当我们定义一个 sum 函数,在后面的多次调用中,它接收的两个参数我们都传的是整形,sum 函数被识别为热点函数,解释器将收集到的类型信息发送给编译器,编译器生成优化后的机器代码,此时当中的类型被定义为整型,在下次的调用中,直接执行机器代码。
而如果在下次的调用中,传入的参数是字符串型,机器代码不知道如何处理,就会返回给解释器解释执行
因此我们尽量不要把一个变量的类型变来变去,这样会对 V8 引擎带来一些影响,损失一定的性能
以上就是 V8 执行 JS 代码的具体流程
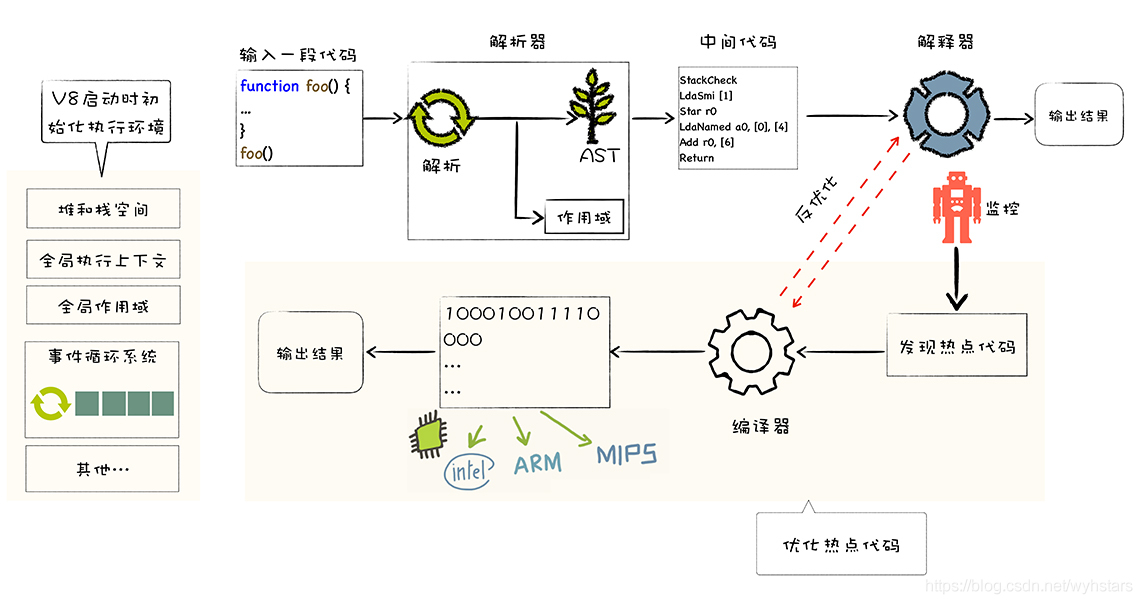
在网上看到的一张图(侵删),很形象,excalidraw 上不去,不然我一定自己做了
参考资料
非常感谢您的阅读,欢迎提出你的意见,有什么问题欢迎指出,谢谢!🎈